@recone https://blog.csdn.net/nju911/article/details/106892983 可以参考一下
-
Tensorflow2.0中文手写字识别---项目复现失败
-
@刘看山 在尝试着做这个,效果不是很理想
-
recone |
@AdolphWang 请问训练py文件怎么运行呢? 我一直报错,utf-8不能被解码
-
刘看山 |
@AdolphWang 你可以自己调整模型,如果你跑通了pipeline的话
-
@刘看山 结果已经出来了呢,只是有点过拟合了,识别率不太高,Windows环境+tensorflow2.4+python3.8
-
刘看山 |
@AdolphWang Windows目前不支持,用Ubuntu,这个项目的数据集在windows下的编码都是失败的
-
上一个问题没有解决,想着只是一个打印消息的代码,就直接屏蔽绕过了;
然后遇到了一个新的问题,在代码84行处,出现了一个编码解析错误,网上扒拉了很久也没能成功解决
 图片地址)
图片地址) -
@刘看山 使用断点调试,可以看到程序执行到第49行时,中止执行,
for data in train_dataset.take(2):
print(data)
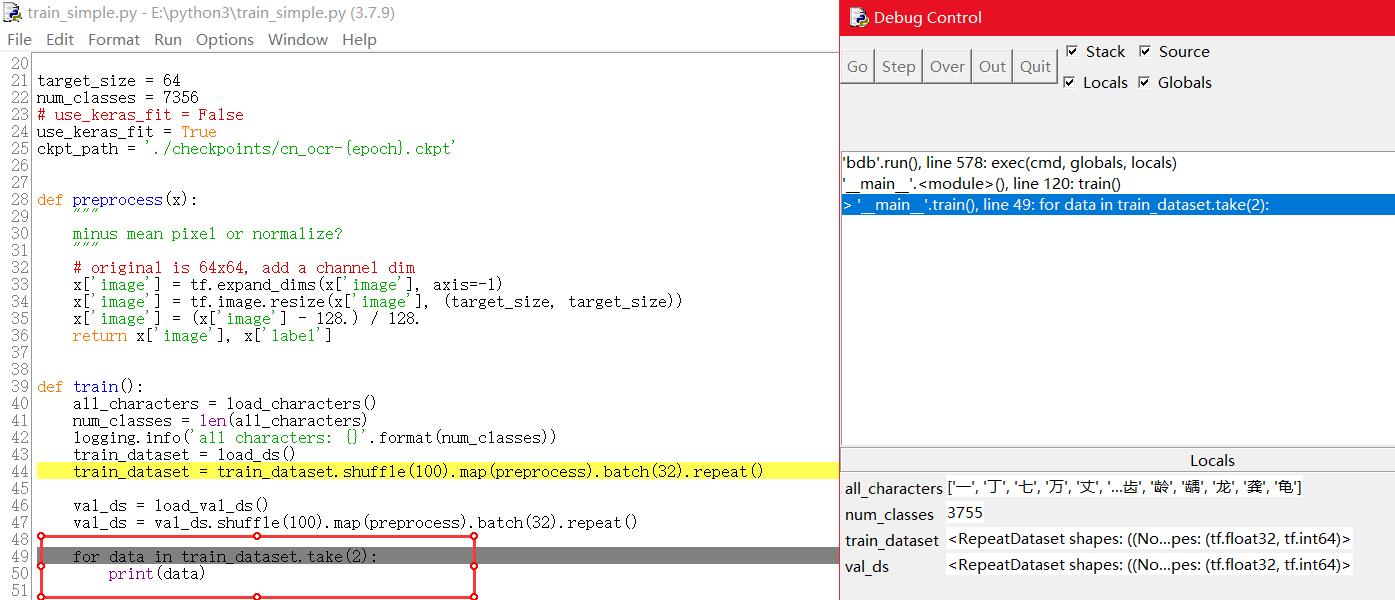
然后,就不知道怎么办了 -
@AdolphWang 最新情况,train_simple.py 程序执行到一半,自动退出,还找不到问题在哪里
-
@刘看山 前面的问题都已经解决了,在运行 train_simple.py时,报错显示 UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 73: invalid continuation byte ,在程序中找到这个 ckpt_path = './checkpoints/cn_ocr-{epoch}.ckpt' ,然后,看不懂了,求大佬指教
-
刘看山 |
你直接把
HWDBtrn_gnt这个文件夹的路径传给程序就可以了;python convertxxx.py HWDBTtrn_gnt代码意思是读取第一个参数也就是你的路径,否则就是没有路径会报错.这个很简单的代码..... 感觉幼儿园毕业的都能理解
-
@刘看山 研究了大半天,大概理清了一些问题:
1、 if len(sys.argv) <= 1:
logging.error('specific your trn_gnt path: python3 convert_to_tfrecord.py {}'.format(
'./hwdb_raw/HWDB1.1trn_gnt/'))每次运行后都会打印 错误信息,表明输入的参数个数 <= 1,即是表明没有成功找到所需文件;
2、搜索.gnt文件代码段:
all_hwdb_gnt_files = glob.glob(os.path.join(p, '*.gnt'))
程序应该是通过该代码片段搜集.gnt文件以转换成.tfrecod文件,但是结果并没有,即是说存放.gnt文件的路径不正确,我有分别放到固定文件夹路径下;
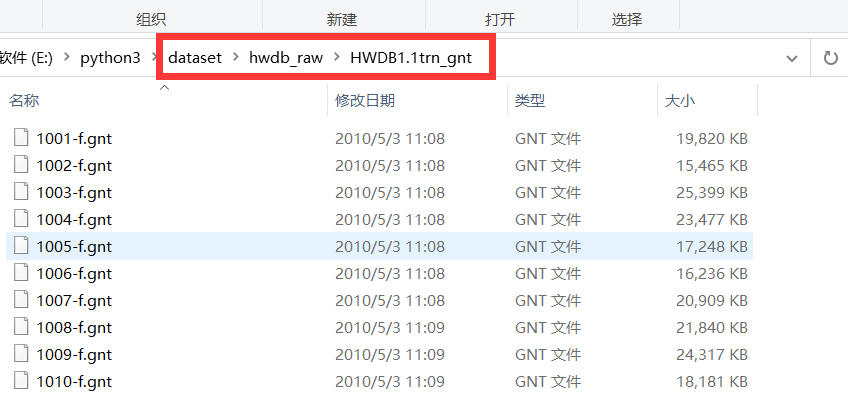
以及python程序文件同级目录下,
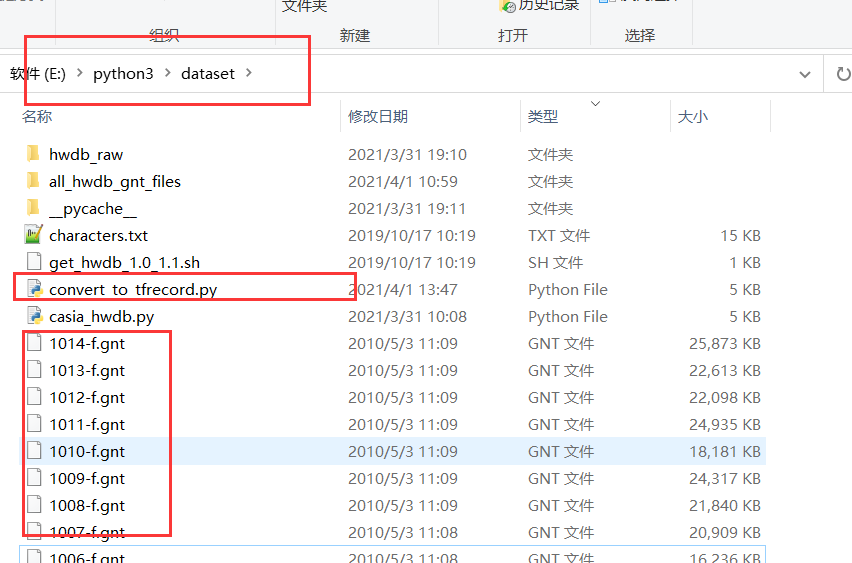
运行皆报错,在此恳请大佬分析一下该如何解决问题,谢谢 -
@刘看山 好的,谢谢大佬
-
刘看山 |
你需要generate 相应的tensorflow record.
具体生成方式可以参考一些其他的对应教程,我们有convert的脚本,你可能需要根据你的路径修改一下,如果实在找不到,就看看里面glob的逻辑,看看它找的是哪些文件.
这个项目是tensorflow的,然后数据集相对来说也比较复杂,你完全看不懂它里面是个啥,包括我也不看不懂.
你先试一下,不懂再问
