曾经在单目深度估计中效果非常不错的monodepth方法现在有了最新的第二个升级版本。先上github链接:
https://github.com/nianticlabs/monodepth2
早在v1版本中,单目深度估计的帧率为18fps(GTX1070),纯C++版本是28fps。最新的v2版本采用pytorch进行实现,本文将持续更新,只要测试几个要点:
- 最新的版本帧率;
- 在kitti上的效果;
- 与常用的DVO方法结合的slam效果。
本文还将在这个项目的基础上实现以下功能:
- libtorch 纯C++推理实现;
- DVO集成。
作为本人在奇点社区的第一篇分享,还是遵循社区的规则,充实以下内容。这篇文章应该是研究slam以及机器人定位的小伙伴看的。
Digging Into Self-Supervised Monocular Depth Estimation
这篇文章写作的动机在于,注意哦,这是一篇非监督的单目深度估计论文. 假如你要做一个监督的深度估计,你去每一个像素值标注深度不会累死去?即便是用深度相机生成的深度图也很难去在上面校正。深度相机生成的深度图普遍比较渣。我们来看一下这篇论文的效果:
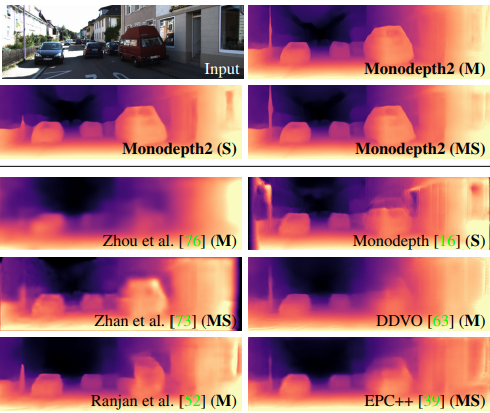
从图可以看出,monodepth2的效果比1好很多,并且更加的细致、密集。
这里有一张非常清晰的对比照:
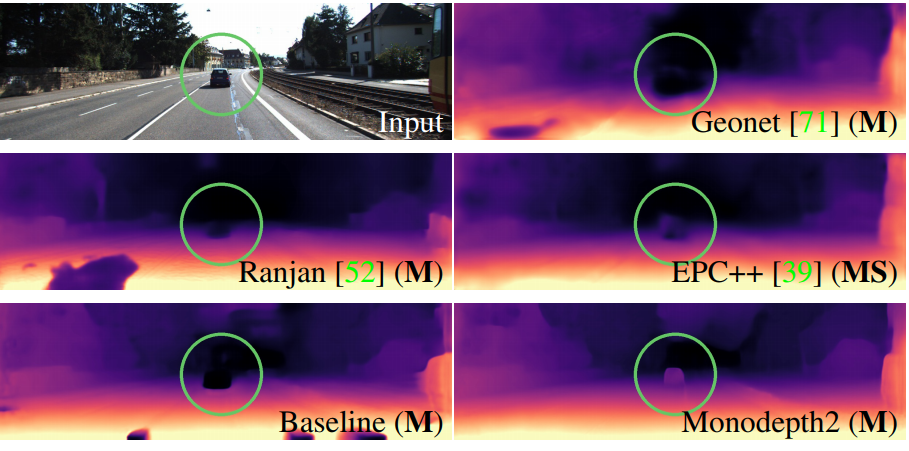
一些深度估计方法,诸如GeoNet等都出现了fail的情况,但是monodepth2却可以非常精准的估计深度。
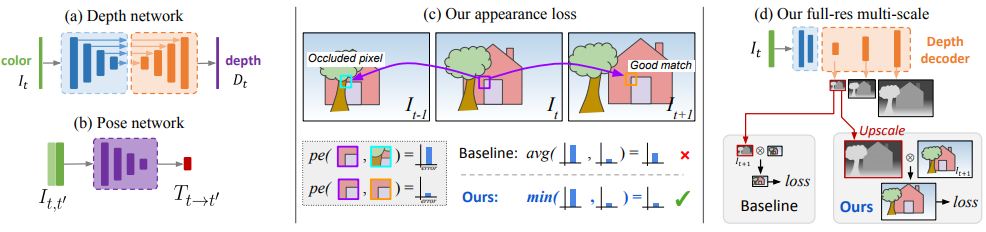
上图是monodepth的核心网络结构。论文中的核心要点可以总结为三点:
- 深度网络:文中提到了一种深度网络,从彩色图得到depth;
- 表观特征loss:很好的处理了被遮挡像素值的预测情况;
- 多尺度同步进行loss:在多个不同尺度上对groudtruth进行loss训练。
实验证明,这个方法十分的有效:

当然,论文中也展示了一些失败案例:

从实际应用来讲,这个效果其实已经十分不错。甚至超过了一些深度相机生成的深度图效果。
