tvm is became more and more popular in deploy deeplearning models. We (manaai authors) did a lot of explorations on it. Here, we record some basic usages and installation steps for new comers to start with.
this tutorial include:
- github repos for our code;
- bilibili video tutorial links;
- tvm installation steps.
Install
First, lets have a quick look on how to install tvm on your PC. Before install, notes you need to know:
- Please install cuda, llvm etc for your PC;
- tvm is highly customizable, please follow instructions below to customize (enviroments), these is not included in official tutorials;
- Please star this link and this website, since you will need this again in the future.
For Ubuntu users:
Or any other unix system users, installation could be:
git clone --recursive https://github.com/apache/tvm.git
cd tvm && mkdir build
ok, then next step is a little bit important. Since you gonna need modification your cmake configs for your system, we can using cmake .. -Dxxx, but this is not good for tvm, since our configs are tooooooo many. So, do this:
# open vscode, edit file of `cmake/config.cmake`
# some values we want edit
# open llvm
set(USE_LLVM ON)
# open cuda
set(USE_CUDA ON)
# open tensorrt
set(USE_TENSORRT_RUNTIME $ENV{HOME}/TensorRT)
这里有一个开箱急用的设置:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#--------------------------------------------------------------------
# Template custom cmake configuration for compiling
#
# This file is used to override the build options in build.
# If you want to change the configuration, please use the following
# steps. Assume you are on the root directory. First copy the this
# file so that any local changes will be ignored by git
#
# $ mkdir build
# $ cp cmake/config.cmake build
#
# Next modify the according entries, and then compile by
#
# $ cd build
# $ cmake ..
#
# Then build in parallel with 8 threads
#
# $ make -j8
#--------------------------------------------------------------------
#---------------------------------------------
# Backend runtimes.
#---------------------------------------------
# Whether enable CUDA during compile,
#
# Possible values:
# - ON: enable CUDA with cmake's auto search
# - OFF: disable CUDA
# - /path/to/cuda: use specific path to cuda toolkit
set(USE_CUDA ON)
# Whether enable ROCM runtime
#
# Possible values:
# - ON: enable ROCM with cmake's auto search
# - OFF: disable ROCM
# - /path/to/rocm: use specific path to rocm
set(USE_ROCM OFF)
# Whether enable SDAccel runtime
set(USE_SDACCEL OFF)
# Whether enable Intel FPGA SDK for OpenCL (AOCL) runtime
set(USE_AOCL OFF)
# Whether enable OpenCL runtime
#
# Possible values:
# - ON: enable OpenCL with cmake's auto search
# - OFF: disable OpenCL
# - /path/to/opencl-sdk: use specific path to opencl-sdk
set(USE_OPENCL OFF)
# Whether enable Metal runtime
set(USE_METAL OFF)
# Whether enable Vulkan runtime
#
# Possible values:
# - ON: enable Vulkan with cmake's auto search
# - OFF: disable vulkan
# - /path/to/vulkan-sdk: use specific path to vulkan-sdk
set(USE_VULKAN OFF)
# Whether enable OpenGL runtime
set(USE_OPENGL OFF)
# Whether enable MicroTVM runtime
set(USE_MICRO OFF)
# Whether enable RPC runtime
set(USE_RPC ON)
# Whether to build the C++ RPC server binary
set(USE_CPP_RPC OFF)
# Whether to build the iOS RPC server application
set(USE_IOS_RPC OFF)
# Whether embed stackvm into the runtime
set(USE_STACKVM_RUNTIME OFF)
# Whether enable tiny embedded graph executor.
set(USE_GRAPH_EXECUTOR ON)
# Whether enable tiny graph executor with CUDA Graph
set(USE_GRAPH_EXECUTOR_CUDA_GRAPH OFF)
# Whether enable pipeline executor.
set(USE_PIPELINE_EXECUTOR OFF)
# Whether to enable the profiler for the graph executor and vm
set(USE_PROFILER ON)
# Whether enable microTVM standalone runtime
set(USE_MICRO_STANDALONE_RUNTIME OFF)
# Whether build with LLVM support
# Requires LLVM version >= 4.0
#
# Possible values:
# - ON: enable llvm with cmake's find search
# - OFF: disable llvm, note this will disable CPU codegen
# which is needed for most cases
# - /path/to/llvm-config: enable specific LLVM when multiple llvm-dev is available.
set(USE_LLVM ON)
#---------------------------------------------
# Contrib libraries
#---------------------------------------------
# Whether to build with BYODT software emulated posit custom datatype
#
# Possible values:
# - ON: enable BYODT posit, requires setting UNIVERSAL_PATH
# - OFF: disable BYODT posit
#
# set(UNIVERSAL_PATH /path/to/stillwater-universal) for ON
set(USE_BYODT_POSIT OFF)
# Whether use BLAS, choices: openblas, atlas, apple
set(USE_BLAS none)
# Whether to use MKL
# Possible values:
# - ON: Enable MKL
# - /path/to/mkl: mkl root path
# - OFF: Disable MKL
# set(USE_MKL /opt/intel/mkl) for UNIX
# set(USE_MKL ../IntelSWTools/compilers_and_libraries_2018/windows/mkl) for WIN32
# set(USE_MKL <path to venv or site-packages directory>) if using `pip install mkl`
set(USE_MKL OFF)
# Whether use MKLDNN library, choices: ON, OFF, path to mkldnn library
set(USE_MKLDNN OFF)
# Whether use OpenMP thread pool, choices: gnu, intel
# Note: "gnu" uses gomp library, "intel" uses iomp5 library
set(USE_OPENMP none)
# Whether use contrib.random in runtime
set(USE_RANDOM ON)
# Whether use NNPack
set(USE_NNPACK OFF)
# Possible values:
# - ON: enable tflite with cmake's find search
# - OFF: disable tflite
# - /path/to/libtensorflow-lite.a: use specific path to tensorflow lite library
set(USE_TFLITE OFF)
# /path/to/tensorflow: tensorflow root path when use tflite library
set(USE_TENSORFLOW_PATH none)
# Required for full builds with TFLite. Not needed for runtime with TFLite.
# /path/to/flatbuffers: flatbuffers root path when using tflite library
set(USE_FLATBUFFERS_PATH none)
# Possible values:
# - OFF: disable tflite support for edgetpu
# - /path/to/edgetpu: use specific path to edgetpu library
set(USE_EDGETPU OFF)
# Possible values:
# - ON: enable cuDNN with cmake's auto search in CUDA directory
# - OFF: disable cuDNN
# - /path/to/cudnn: use specific path to cuDNN path
set(USE_CUDNN OFF)
# Whether use cuBLAS
set(USE_CUBLAS OFF)
# Whether use MIOpen
set(USE_MIOPEN OFF)
# Whether use MPS
set(USE_MPS OFF)
# Whether use rocBlas
set(USE_ROCBLAS OFF)
# Whether use contrib sort
set(USE_SORT ON)
# Whether use MKL-DNN (DNNL) codegen
set(USE_DNNL_CODEGEN OFF)
# Whether to use Arm Compute Library (ACL) codegen
# We provide 2 separate flags since we cannot build the ACL runtime on x86.
# This is useful for cases where you want to cross-compile a relay graph
# on x86 then run on AArch.
#
# An example of how to use this can be found here: docs/deploy/arm_compute_lib.rst.
#
# USE_ARM_COMPUTE_LIB - Support for compiling a relay graph offloading supported
# operators to Arm Compute Library. OFF/ON
# USE_ARM_COMPUTE_LIB_GRAPH_EXECUTOR - Run Arm Compute Library annotated functions via the ACL
# runtime. OFF/ON/"path/to/ACL"
set(USE_ARM_COMPUTE_LIB OFF)
set(USE_ARM_COMPUTE_LIB_GRAPH_EXECUTOR OFF)
# Whether to build with Arm Ethos-N support
# Possible values:
# - OFF: disable Arm Ethos-N support
# - path/to/arm-ethos-N-stack: use a specific version of the
# Ethos-N driver stack
set(USE_ETHOSN OFF)
# If USE_ETHOSN is enabled, use ETHOSN_HW (ON) if Ethos-N hardware is available on this machine
# otherwise use ETHOSN_HW (OFF) to use the software test infrastructure
set(USE_ETHOSN_HW OFF)
# Whether to build with Arm(R) Ethos(TM)-U NPU codegen support
set(USE_ETHOSU OFF)
# Whether to build with TensorRT codegen or runtime
# Examples are available here: docs/deploy/tensorrt.rst.
#
# USE_TENSORRT_CODEGEN - Support for compiling a relay graph where supported operators are
# offloaded to TensorRT. OFF/ON
# USE_TENSORRT_RUNTIME - Support for running TensorRT compiled modules, requires presense of
# TensorRT library. OFF/ON/"path/to/TensorRT"
set(USE_TENSORRT_CODEGEN ON)
set(USE_TENSORRT_RUNTIME $ENV{HOME}/TensorRT))
# Whether use VITIS-AI codegen
set(USE_VITIS_AI OFF)
# Build Verilator codegen and runtime
set(USE_VERILATOR OFF)
# Build ANTLR parser for Relay text format
# Possible values:
# - ON: enable ANTLR by searching default locations (cmake find_program for antlr4 and /usr/local for jar)
# - OFF: disable ANTLR
# - /path/to/antlr-*-complete.jar: path to specific ANTLR jar file
set(USE_ANTLR OFF)
# Whether use Relay debug mode
set(USE_RELAY_DEBUG OFF)
# Whether to build fast VTA simulator driver
set(USE_VTA_FSIM OFF)
# Whether to build cycle-accurate VTA simulator driver
set(USE_VTA_TSIM OFF)
# Whether to build VTA FPGA driver (device side only)
set(USE_VTA_FPGA OFF)
# Whether use Thrust
set(USE_THRUST OFF)
# Whether to build the TensorFlow TVMDSOOp module
set(USE_TF_TVMDSOOP OFF)
# Whether to use STL's std::unordered_map or TVM's POD compatible Map
set(USE_FALLBACK_STL_MAP OFF)
# Whether to use hexagon device
set(USE_HEXAGON_DEVICE OFF)
set(USE_HEXAGON_SDK /path/to/sdk)
# Hexagon architecture to target when compiling TVM itself (not the target for
# compiling _by_ TVM). This applies to components like the TVM runtime, but is
# also used to select correct include/library paths from the Hexagon SDK when
# building offloading runtime for Android.
# Valid values are v60, v62, v65, v66, v68.
set(USE_HEXAGON_ARCH "v66")
# Whether to use ONNX codegen
set(USE_TARGET_ONNX OFF)
# Whether enable BNNS runtime
set(USE_BNNS OFF)
# Whether to use libbacktrace
# Libbacktrace provides line and column information on stack traces from errors.
# It is only supported on linux and macOS.
# Possible values:
# - AUTO: auto set according to system information and feasibility
# - ON: enable libbacktrace
# - OFF: disable libbacktrace
set(USE_LIBBACKTRACE AUTO)
# Whether to build static libtvm_runtime.a, the default is to build the dynamic
# version: libtvm_runtime.so.
#
# The static runtime library needs to be linked into executables with the linker
# option --whole-archive (or its equivalent). The reason is that the TVM registry
# mechanism relies on global constructors being executed at program startup.
# Global constructors alone are not sufficient for the linker to consider a
# library member to be used, and some of such library members (object files) may
# not be included in the final executable. This would make the corresponding
# runtime functions to be unavailable to the program.
set(BUILD_STATIC_RUNTIME OFF)
# Caches the build so that building is faster when switching between branches.
# If you switch branches, build and then encounter a linking error, you may
# need to regenerate the build tree through "make .." (the cache will
# still provide significant speedups).
# Possible values:
# - AUTO: search for path to ccache, disable if not found.
# - ON: enable ccache by searching for the path to ccache, report an error if not found
# - OFF: disable ccache
# - /path/to/ccache: use specific path to ccache
set(USE_CCACHE AUTO)
# Whether to enable PAPI support in profiling. PAPI provides access to hardware
# counters while profiling.
# Possible values:
# - ON: enable PAPI support. Will search PKG_CONFIG_PATH for a papi.pc
# - OFF: disable PAPI support.
# - /path/to/folder/containing/: Path to folder containing papi.pc.
set(USE_PAPI OFF)
for tensorrt, we assume you installed tensorrt to your ~/TensorRT folder.
then:
cp cmake/cmake.config build
then you can cmake .. and build.
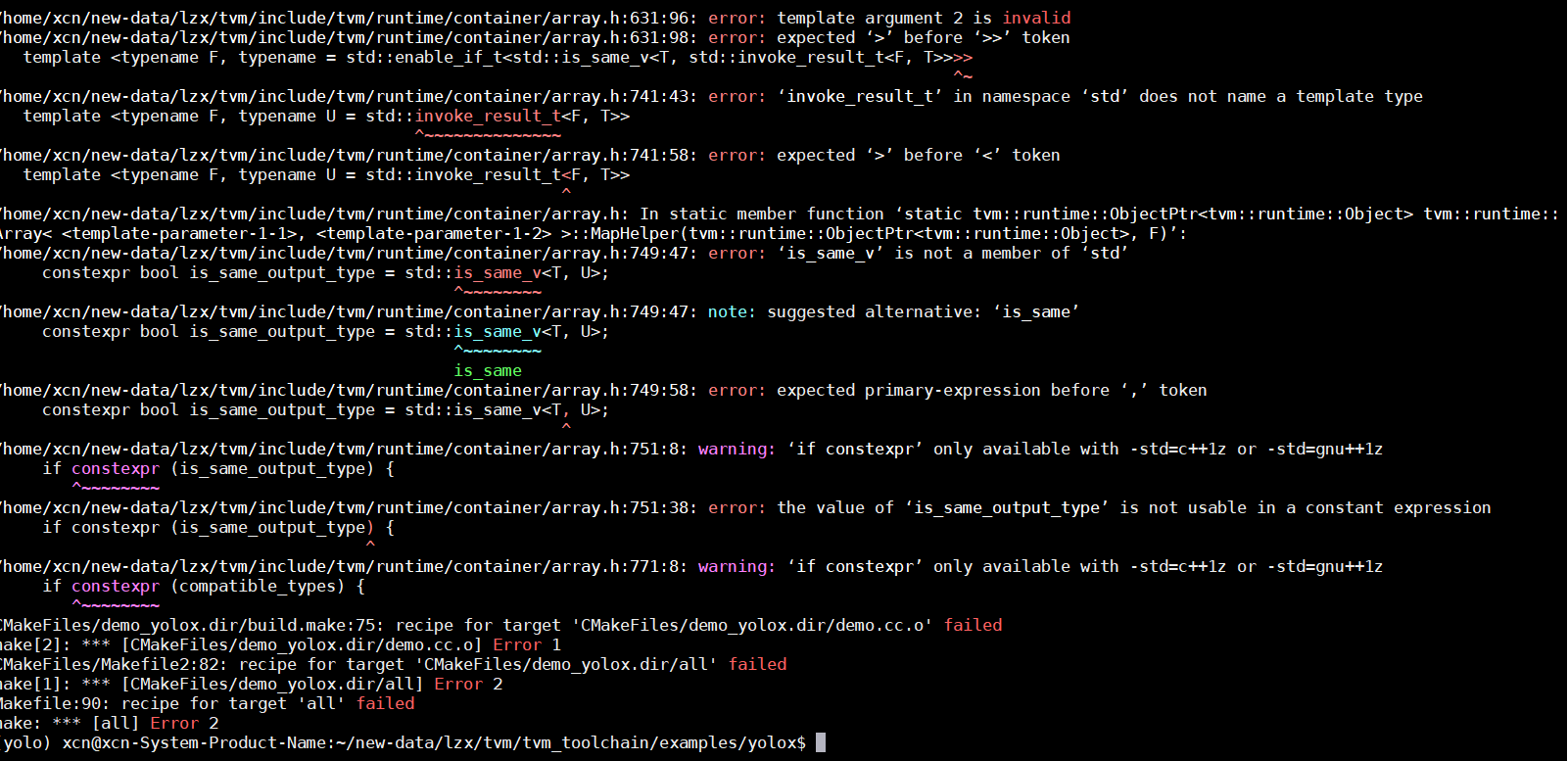
如果编译的时候遇到这个问题:
tvm/cmake/libs/../../3rdparty/libbacktrace/configure: not found
make[2]: *** [CMakeFiles/project_libbacktrace.dir/build.make:109: libbacktrace/src/project_libbacktrace-stamp/project_libbacktrace-configure] Error 127
make[1]: *** [CMakeFiles/Makefile2:1011: CMakeFiles/project_libbacktrace.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
那么可以直接disable 这个backtrace的依赖:
set(USE_LIBBACKTRACE AUTO) -> set(USE_LIBBACKTRACE OFF)
更新:
2021.10.08: 貌似现在需要用ninja来默认变异了,直接安装下ninja,然后ninja -j8
Github Repo
We have released a good tool for you to start with tvm:
https://github.com/jinfagang/tvm_edge
this code we provide many popular models implementation in tvm, and finally, we want make it all infernce using tvm and C++, models such as:
- yolov5;
- yolox;
- scrfd.
etc.
tvm教程
接下来是持续更新的tvm部署基本流程.
0x1. tvm模型转换,从onnx, pytorch, keras, pb, tflite等
其实网上那些写代码的转换方式都没有必要,直接用tvmc:
pip install xgboost
tvmc tune a.onnx -o a.tar --target cuda
比如,我们转换DETR的onnx模型到GPU,就可以使用:
tvmc tune detr-r50_sim.onnx --target cuda -o detr_cuda.tar
这个地方需要注意,tune这个命令,生成的东西实际上是tuning_records:
tvmc tune yolox.torchscript.pt --model-format pytorch -o yolox.tuning.records --target cuda --input-shapes 'x:[1,3,512,512]' --number 120 --repeat 129
也就是说tune完之后需要compile,并且指定这个tuning_records
请注意,这里是会对模型进行tune,tune会需要很长的时间,假如你不想tune,只是想测试一下逻辑.那么可以用tvmc compile 其他的一样.
tvmc tune detr-r50_sim.onnx --target cuda -o detr_cuda.tar
[20:03:59] /schedule/bound.cc:119: not in feed graph consumer = compute(placeholder_red_temp.repl, body=[reduce(combiner=comm_reducer(result=[select(((argmax_lhs_1 > argmax_rhs_1) || ((argmax_lhs_1 == argmax_rhs_1) && (argmax_lhs_0 < argmax_rhs_0))), argmax_lhs_0, argmax_rhs_0), select((argmax_lhs_1 > argmax_rhs_1), argmax_lhs_1, argmax_rhs_1)], lhs=[argmax_lhs_0, argmax_lhs_1], rhs=[argmax_rhs_0, argmax_rhs_1], identity_element=[-1, -3.40282e+38f]), source=[placeholder_red_temp.rf.v0[k2.inner.v, ax0, ax1], placeholder_red_temp.rf.v1[k2.inner.v, ax0, ax1]], init=[], axis=[iter_var(k2.inner.v, range(min=0, ext=32))], where=(bool)1, value_index=0), reduce(combiner=comm_reducer(result=[select(((argmax_lhs_1 > argmax_rhs_1) || ((argmax_lhs_1 == argmax_rhs_1) && (argmax_lhs_0 < argmax_rhs_0))), argmax_lhs_0, argmax_rhs_0), select((argmax_lhs_1 > argmax_rhs_1), argmax_lhs_1, argmax_rhs_1)], lhs=[argmax_lhs_0, argmax_lhs_1], rhs=[argmax_rhs_0, argmax_rhs_1], identity_element=[-1, -3.40282e+38f]), source=[placeholder_red_temp.rf.v0[k2.inner.v, ax0, ax1], placeholder_red_temp.rf.v1[k2.inner.v, ax0, ax1]], init=[], axis=[iter_var(k2.inner.v, range(min=0, ext=32))], where=(bool)1, value_index=1)], axis=[iter_var(ax0, range(min=0, ext=1)), iter_var(ax1, range(min=0, ext=100))], reduce_axis=[iter_var(k2.inner.v, range(min=0, ext=32))], tag=, attrs={})
[Task 1/52] Current/Best: 194.46/ 355.44 GFLOPS | Progress: (9/19) | 38.57 s Done.
[Task 2/52] Current/Best: 0.00/ 0.00 GFLOPS | Progress: (0/19) | 0.00 s