FCOS: Fully Convolutional One-Stage Object Detection
本文首发来自于奇点AI社区, 最新论文速递模块: http://talk.strangeai.pro/compose?p=/category/16/
这篇论文是阿德莱德的一个大学组做的, 也就是来自于澳大利亚, 我们的MANA AI社群就有一位来自阿德莱德朋友, 怪不得他能认出我们用的一些演示视频场景就来自于阿德莱德.
今天我们重新读一遍阿德莱德这篇论文. 其实FCOS这篇论文, 是在maskrcnn-benchmark这个项目的基础上改的. 站在巨人的肩膀上, 出成果果然快, 这篇论文还是有很多可圈可点的地方, 不放借助这个项目, 来加深对maskrcnn-benchmark的理解.
摘要
我们提出了一个全卷积的单阶段目标检测方法来解决目标检测问题, 并且是以每一个像素预测的方式, 这跟语义分割可以类比. 目前几乎所有的目标检测方法, 比如RetinaNet, SSD, YoloV3等都需要自己预先定义anchor. 相反, 在FCOS方法中, 我们不需要定义anchor, 也不需要进行proposal区域建议. 由于我们没有采用anchor的方式, 使得我们不需要进行一些anchor相关的计算, 比如在训练的时候计算overlapping, 因此我们在训练的时候会非常的节省内存. 更重要的是, 我们这个方法可以大大的减少超参数的调解, 你几乎不要调参啊. 仅仅只要一个nms, 我们就可以得到和一些state of art的方法类似的准确率, 即便我们使用的方法更加的简单. 我们希望这个方法未来能够成为一个通用的实例级别的任务框架.
介绍
本文也提出了三点重点:
- 不需要太花哨的手法, FCOS方法就可以取得类似于RPN一样的效果, 并且精度不会太差;
- 我们希望社区的朋友能够重新思考anchor的必要性, 这在业内已经成为了公认的标准;
- 我们提出的方法只需要改动一点点, 就可以实现诸如实例分割, 关键点检测之类的任务.
架构
FCOS的整体网络架构, 首先通过3个高层产生高分辨率特征图, 然后采用top-down的结果, 从C5开始向上和向下延伸出不同大小和抽象程度的特征图, 也就是生成了P3, P4, P5, P6, P7, 这些特征图进一步的连接Head头部结构, 这个Head头部结构本质上就是一个小型的回归器, 回归的目标包括: 类别, 是否是中心点, 以及距离目标top和left的距离和这个点的x,y坐标.
如下图所示:
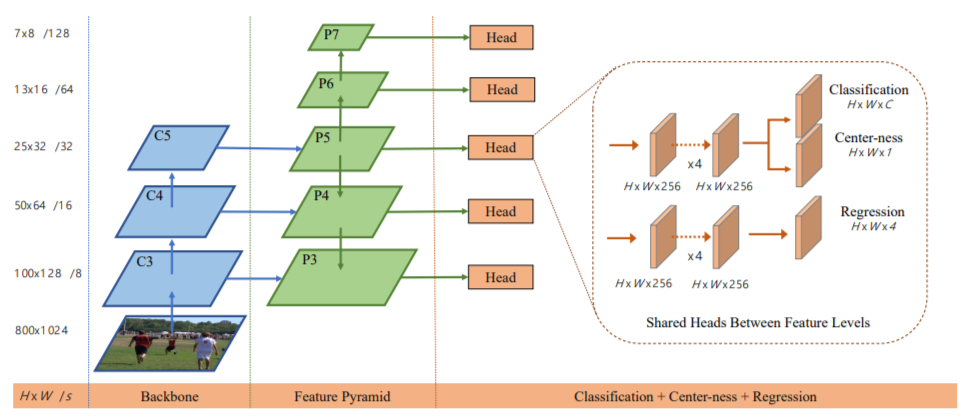
看到这里我们基本上明白了. 这个网络利用了多层次特征互补, 并且在每一个特征曾都会连接一个头部回归网络进行回归, 总共有5个回归器.
更进一步的, 我们提出的在P3-P7的特征层上做回归, 最终会在同一个头部结构内进行回归, 进行权值共享.P3-P7 的strides分别是 8, 16, 32, 64, 128, 你可以看到, 步长越长, 那么生成的特征图就越小, 到了P7, 特征图就很小了.
那么我们是如何使得多个头部网络权值共享的呢? 这里要注意的是, 不同于传统的基于anchor的目标检测方法, FCOS是通过在每个featuremap的尺度上回归不同尺度的物体, 比如, 在抽象高的高层次特征图上预测大小更小的物体, P7预测size更小的物体, 但是如何界定这个尺寸范围呢? 文章进一步的提出了不同的max size, 也就是说m1, m2, m3, m4, m5, m6, m7 分别对应的是7个不同featuremap大小的特征层次. 这7 个值分别设置维: 0, 64, 128, 256, 512, 和无穷大.
要说明的是, 这里面虽然最后的头部是权值共享的, 但是也不是完全的一样, 其中设定了一个参数, 使得不同的特征可以自适应的更新相对应的权重.
最后比较重要的是这个centerness的概念, 我们知道, 在我们的网络里面,其中很重要的一个环节就是预测某一个点是否是中心点, 准确的说, 是否是中心点的概率, 它的值是[0, 1], 比如我们用从中心店到两侧, 分别对每一个点的概率进行可视化, 组成热力图, 可以看到预测效果应该是:

这个就是objectness的预测效果. 并且在预测的时候, 这个centerness的得分会乘以预测的物体的概率, 起到了双重保险的效果.
最后, 引出一个小学生都知道的公式, 我们训练的时候是怎么从box得到centerness从而指导网络预测的呢? 答案很简单:
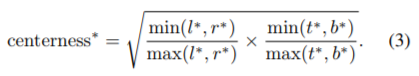
没错, 这个公式就是说, 当box里面的某个点, 它越接近中心点, 它的这个值就越接近与1, 越靠近边界,它就值就越接近与0.
由于这个值是0-1的回归量, 因此训练的时候可以用BCE loss进行训练. (二值交叉熵). ** 这个centerness的应用可以说是本文的核心要点, 它实现了一石二鸟的作用**:
- 我可以判断每一个点是否是一个物体的中心点, 这样中心点确定之后, 框的预测任务我就完成了50%;
- 另外由于对于每一个点还有一个class的score, 其实中心点可能有很多, 通过centerness和class的得分再乘一下, 均匀掉低置信度的中心点. 从而进一步提升框的回归可靠度.
最后还得提一下, 这个centerness不是必须的, 你也可以不用centerness来实现FCOS. 没有centerness, 那么预测每个点的class score, 以及坐标, 但是由于你无法确定中心点, 接下来的工作就只能类似的通过FCN分割的方式来做了, 但是不加centerness跟加上centerness, 有着 3%个点的gap, 即加上centerness可以从33.8% map飙升到 36%, 这个提升就得以与centerness.
从结果可以看出, 其在小物体上的检测效果还是非常不错的:

本文来自奇点AI社区, 论文速递, talk.strangeai.pro , 同时也欢迎大家关注我们的AI代码算法平台:manaai.cn
