-
-
 makes
发布在 社区博客 • 阅读更多
makes
发布在 社区博客 • 阅读更多曾经在单目深度估计中效果非常不错的monodepth方法现在有了最新的第二个升级版本。先上github链接:
https://github.com/nianticlabs/monodepth2
早在v1版本中,单目深度估计的帧率为18fps(GTX1070),纯C++版本是28fps。最新的v2版本采用pytorch进行实现,本文将持续更新,只要测试几个要点:
- 最新的版本帧率;
- 在kitti上的效果;
- 与常用的DVO方法结合的slam效果。
本文还将在这个项目的基础上实现以下功能:
- libtorch 纯C++推理实现;
- DVO集成。
作为本人在奇点社区的第一篇分享,还是遵循社区的规则,充实以下内容。这篇文章应该是研究slam以及机器人定位的小伙伴看的。
Digging Into Self-Supervised Monocular Depth Estimation
这篇文章写作的动机在于,注意哦,这是一篇非监督的单目深度估计论文. 假如你要做一个监督的深度估计,你去每一个像素值标注深度不会累死去?即便是用深度相机生成的深度图也很难去在上面校正。深度相机生成的深度图普遍比较渣。我们来看一下这篇论文的效果:
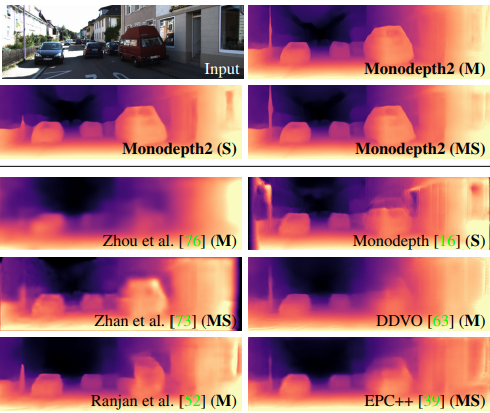
从图可以看出,monodepth2的效果比1好很多,并且更加的细致、密集。
这里有一张非常清晰的对比照: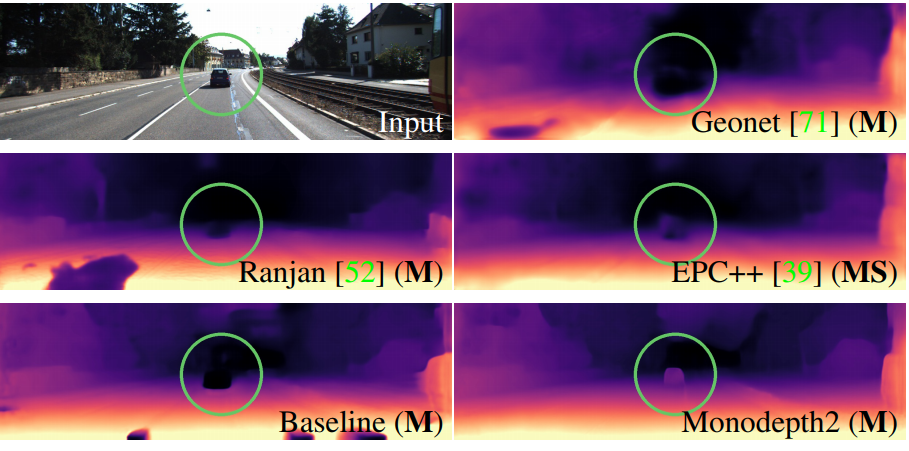
一些深度估计方法,诸如GeoNet等都出现了fail的情况,但是monodepth2却可以非常精准的估计深度。
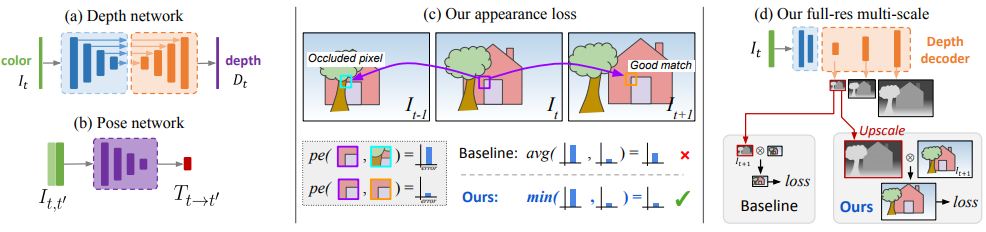
上图是monodepth的核心网络结构。论文中的核心要点可以总结为三点:
- 深度网络:文中提到了一种深度网络,从彩色图得到depth;
- 表观特征loss:很好的处理了被遮挡像素值的预测情况;
- 多尺度同步进行loss:在多个不同尺度上对groudtruth进行loss训练。
实验证明,这个方法十分的有效:

当然,论文中也展示了一些失败案例:

从实际应用来讲,这个效果其实已经十分不错。甚至超过了一些深度相机生成的深度图效果。
-
-
-
-
makes
发布在 恋爱&&相亲(程序员福利) • 阅读更多
92年的,178,75kg。老家辽宁的,东北汉子,希望在这里遇到合适的女孩子。感兴趣的欢迎私聊我,这里不好留微信号。照片如下:

平时喜欢听歌,看电影,爬山。
职业是程度员。 -
makes
发布在 3D目标检测 • 阅读更多
绘制俯视图在进行3D检测领域是很有必要的一个操作,现在的一些3D检测方法,比如MVD,AVOD,SECOND, PIXOR,都采用bev map作为主要的参考对象,那么为什么bev这么有用呢?
BEV Map必要性
原因其实十分简单,比如说,下面的这张图:

就是一张俯视图,它对应的点云图如下所示:

我们会发现,假如我们直接对点云进行处理,那么计算量是比较大的。此时计算速度会很慢,比如avod方法,处理一针点云需要2s,这个速度在实际场合根本无法使用。
因此另外一些算法转而采用bev来进行特征的抽取,然后直接生成3D的目标坐标。那么此时就得思考一个问题:bev map是否包含足够的信息让网络学习?. 事实上,俯视图用来检测车辆是很不错的。从生成的俯视图也可以看出,对于车辆的特征非常明显。而且用这个方式来做还有一个好处:受激光点云线数影响不大, 为什么呢?因为它是从上往下的投影,因此对于64线和16线,虽然在分辨率上会有些差别,但是物体的形态基本上是没有太大的变化的。
如何生成俯视图
其实从点云生成俯视图的原理也非常简单,基本上就是将点云里面每个点的z点作为像素值,映射到图片里面去。
总共分为三个步骤:- Crop the point cloud to certain range, like left-right range, back-forward range;
- Shifting x, y values to min be 0;
- Mapping z to image pixel values.
-
-


