-
VincentKan发布在 社区求助区(SOS!!) • 阅读更多
@xinzaiyan 在 Tensorflow2.0中文手写字识别 UnicodeDecodeError 中说:
@VincentKan 请问你这个问题怎么解决的呀,我也遇到了

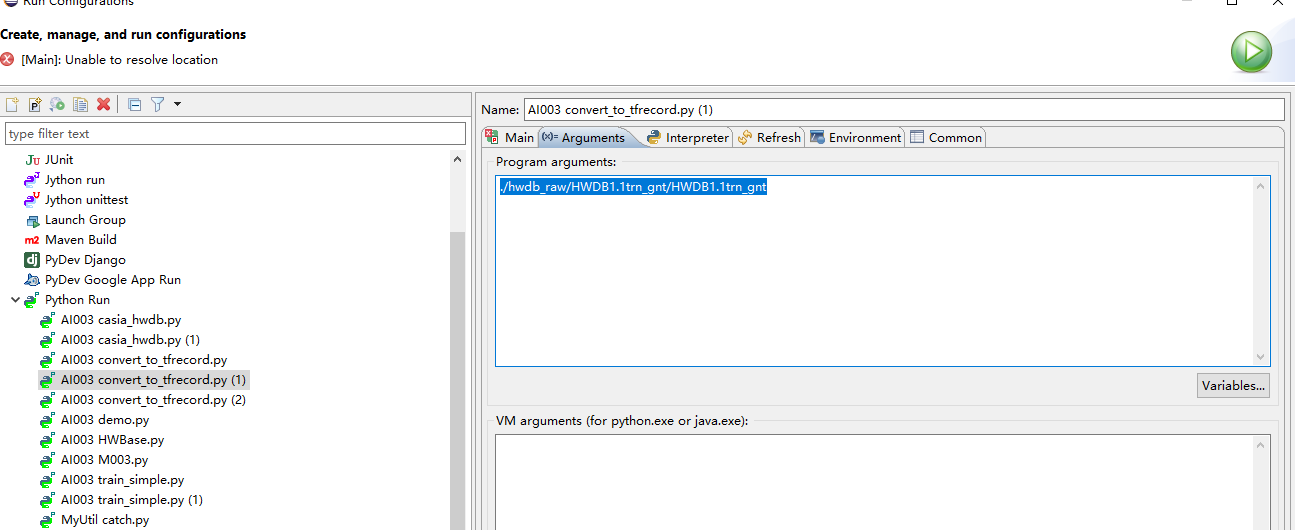
问题都出在生成TFrecord的程序中,正确的数据准备结构如下图:注意HWDB的文件夹位置,然后在跑程序的时候,参数设置好:

-
VincentKan发布在 社区求助区(SOS!!) • 阅读更多
已经解决,目前项目可以正常学习了。
问题在于:作者在项目介绍中有几个疏漏:
1、使用的数据是1.1版本,并不是1.0版本
2、运行convert to tfrecord程序时,要运行两次,分别给训练集和测试集的地址,这样才能生成出2个tfrecord
3、如果大家下载是从文章中的链接下载了原始数据,那么一定要把路径设置正确,不能直接运行程序生成tfrecord文件
以上,祝各位也能成功~
BTW,我跑了50个epoch,训练集已经90%的准确率了,还不错哦~ 接下来可以开始网络模型设计了! -
VincentKan发布在 社区求助区(SOS!!) • 阅读更多
Tensorflow2.0中文手写字识别
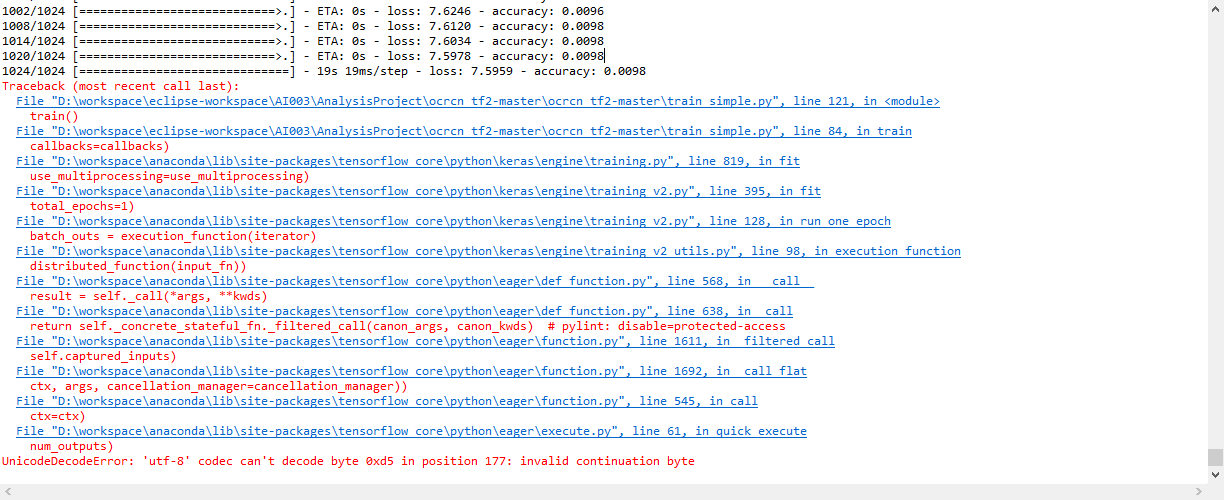
跑了1个Epoch后报错“UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd5 in position 177: invalid continuation byte” 请问有人遇见过这个问题吗?(win10系统)