-
 刘看山
发布在 社区博客 • 阅读更多
刘看山
发布在 社区博客 • 阅读更多本教程首发自神力AI社区,转载请保留出处,谢谢合作!太阳系最大的AI代码市场:http://manaai.cn
深度学习安装宝典,你值得拥有。
装环境是最头疼的一件事情。很多时候会遇到莫名其妙的问题。这篇文章推荐深度学习入门者看,主要是如何搭建标准的深度学习环境。我们从容易到难,逐渐叫大家如何构建,内容将包括目前比较主流的所有深度学习框架。其中也将包括不同的平台,比如windows,linux,macos。
CUDA
从最麻烦,也是最基础的开始,加入你没有cuda设备,可以忽略这一步。如果你有显卡,如果支持cuda,那么可以安装一下cuda驱动,开始你的深度学习之旅。
网上很多教程,要么很老,要么按部就班,大家按照步骤装完了发现一对错误。本质上是没有事先告诉大家在装之前可能会踩的坑。这里我作为过来人,给新手总结一些要点:
- 本教程会一直更新,目前最新的是cuda10,我建议直接安装cuda10.0,不要整什么cuda10.1或者10.2. 下面会告诉大家为什么;
- cuda安装去英伟达官网下载,不要选择最新的,从legacy里面选择历史版本,然后下载对应平台的,windows下好办,直接exe,linux下选择.run文件;
- cudnn要实现注册英伟达账号,下载那个tar.gz的压缩包,解压出来就是头文件和动态链接库,拷贝到cuda对应目录即可,非常简单。
- 运行.run文件的时候,不要安装它自带的驱动,也不要安装opengl。
其中最重要的是最后一点,CUDA和英伟达驱动是两个东西, 很多人装完cuda就觉得驱动装完了,结果进不去桌面。这里我建议新手一定要:在安装cuda之前,先把英伟达驱动安装了.
nvidia的driver安装也很简单,以ubuntu为例子,直接添加源,然后
sudo apt install nvidia-driver-410即可。主要CUDA10一般用的是410.- CUDA下载地址:https://developer.nvidia.com/cuda-downloads?
- CUDNN 下载地址:https://developer.nvidia.com/cudnn
有时间我分享一个cuda10.0和cudnn7.5的百度云盘备用链接,不过直接从英伟达官网下载速度也是杠杠的。
Pytorch
总最简单的开始。直接上官网安装:
https://pytorch.org/get-started/locally/
根据自己的系统版本选择对应的安装。这里注意几点:
- 最好用1.1。0,因为这是最新的稳定版本,不要用老版本了;
- 注意python版本和你用的cuda版本。
一般来说,使用pytorch比tensorflow简单一些。安装完成pytorch之后,再安装一下torchvision即可。
源码编译Pytorch
这部分不建议新手看,因为坑很深。我记录一下pytorch源码编译的过程。
- git clone pytorch
首先clonepytorch。注意有submodules,要init
git clone http://github.com/pytorch/pytorch cd pytorch git submodule update --init --recursive # 此时会有thirdparty的库被pull下来 mkdir build_libtorch cd build_libtorch python ../tools/build_libtorch.py- 如果出错了
如果出错,没有猜错的话可能的原因是multidefine什么东西,这个是MKLDNN造成的,解决的办法就是disbale掉它,并且关闭test:
export USE_MKLDNN=0 export BUILD_TEST=0在编译的时候export一下即可。
一般情况下就可以成功编译libtorch,把你编译的库,全部替换掉官方的lib,你的lib就可以用新的ABI了。好像就没了。。。
源码编译pytorch原因主要是两个:- 官方的libtorch用的是gcc4.9编译的,而且使用很老的ABI;
- 源码编译可以加深你对这个库的理解。
更新一下,现在pytorch官网也放出了C++11 ABI的预编译版本,大家可以直接下载用,只有当你需要使用cuda10.1或者不同的cuda版本的时候可以从源码编译。其他的时候没啥问题。
Update 2019.9.10:
上面讲述的是编译libtorch,但是,有时候我们需要编译pytorch,此时命令有点不同,截止到最新的pytorch1.3,编译pytorch的方式为:
USE_MKLDNN=0 USE_DISTRIBUTED=0 sudo -E python3 setup.py install --cmake请注意,这里由于加了sudo,需要添加
-E才能让前面的变量有效,否则无效,无法编译。TensorFlow
tensorflow的安装和编译目前来说还不是那么的蛋疼,加入你成功的安装了cuda和cudnn,那么直接从pip安装gpu版本的问题不大。大家注意两点:
- 不建议用anaconda,我在年轻的时候也用anaconda,那时原因是实验室网速慢,pip慢,甚至还不会换源,假如你看到这篇博客,说明你比那个时候的我要强,可以不用anaconda了。
- 直接从pip安装,如果你要老版本,那就1.19,如果你要tensorflow2.0,那就安装beta版本。
源码编译TensorFlow
简单的指导一下如何从源码编译tensorflow,有时候C++源码的tensorflow还是很有用的。那么要编译也很简单:
1. Install bazel 从bazel官网下载安装,请注意,**tensorflow只支持2.3版本的bazel,高版本的不支持。 **注意**, 截止到2020.05.05, bazel可以直接从apt安装了,但是需要添加对应的apt-key,进入到bazel官网:https://docs.bazel.build/versions/master/install-ubuntu.html > sudo apt install curl > curl https://bazel.build/bazel-release.pub.gpg | sudo apt-key add - > echo "deb [arch=amd64] https://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.list > > sudo apt update > sudo apt install bazel-3.0.0 2. Clone TensorFlow source 从tensorflow官方代码仓库克隆源代码。 3. 两个命令编译 ./configure # 此时需要enable cuda,xla等东西 bazel build -c opt --copt=-mfpmath=both --copt=-msse4.2 --config=cuda //tensorflow:libtensorflow.so bazel build -c opt --copt=-mfpmath=both --copt=-msse4.2 --config=cuda //tensorflow:libtensorflow_cc.so bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package # if build tensorflow 2.0 bazel build --config=v2 //tensorflow/tools/pip_package:build_pip_package
OK. 差不多就行了,最好切换带相应的分支编译,不要从master开始编译。
最后将编译python package:[14:15:33] fagangjin:tensorflow git:(2c319fb) $ ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg然后你就可以看到如下输出:
Fri Jul 19 14:15:38 HKT 2019 : === Preparing sources in dir: /tmp/tmp.E0ITrWBmGN /media/fagangjin/wd/permanent/software/source_codes/dl/tensorflow Fri Jul 19 14:15:53 HKT 2019 : === Building wheel /usr/local/lib/python3.5/dist-packages/setuptools/dist.py:472: UserWarning: Normalizing '2.0.0alpha0' to '2.0.0a0' warning: no files found matching '*.h' under directory 'tensorflow/include/tensorflow' warning: no files found matching '*' under directory 'tensorflow/include/Eigen' warning: no files found matching '*.h' under directory 'tensorflow/include/google' warning: no files found matching '*' under directory 'tensorflow/include/third_party' warning: no files found matching '*' under directory 'tensorflow/include/unsupported' Fri Jul 19 14:16:20 HKT 2019 : === Output wheel file is in: /tmp/tensorflow_pkg更新
- 2019.10.09: 由于tensorflow更新了2.0,因此master branch直接默认是2.0.通过这个方式:
bazel build //tensorflow/tools/pip_package:build_pip_package ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkgCaffe
这里再总结一下如何编译安装caffe。理论上来说,caffe的问题不是它的代码,它的代码其实很健壮,问题在于它的依赖。我见过最多的问题来自于:
- protobuf
- boost
我不告诉你安装步骤,你自己去官方编译,98%会出错,而且错误摸不到头脑。
其实我们MANA平台是有一个自己fork的caffe版本的,里面很多层比如FasterRCNN,RFCN,SSD,YOLO等的纯C++和CUDA支持。由于内部原因可能暂时不会开源。
但现在caffe维护最积极的应该还是BVLC的版本git clone https://github.com/BVLC/caffe号外:
我们发布了一个我们自己维护和修改的caffe版本,整体来讲增加了几乎所有层的支持。ONNXRuntime
onnxruntime 编译比较麻烦,大家可以转到对应的文章进行编译。
跳转到这里来进行 链接MXNet
mxnet的安装直接pip,比较简单。
-
刘看山
发布在 社区求助区(SOS!!) • 阅读更多
@mindmad You can check FPN+SSD model from MANA platform: http://manaai.cn/aicodes_detail3.html?id=41
-
刘看山
发布在 社区博客 • 阅读更多
libfacedetection这个库应该都听过,但是在这之前它只是开源了动态链接库,现在,源代码已经开源了!!!!
这个人脸检测有哪些优势?- 1500fps!!!这个速度非常牛逼了,即便是CPU降低十倍速度也能达到150fps!! CPU realtime!!
- 不依赖于其他任何C++库,这个非常不错,比一些各种依赖的方法好很多!!
- 本次开源了caffe model以及模型的prototxt。
- 支持opennin加速。
闲话不多说,先上github链接:https://github.com/ShiqiYu/libfacedetection
评测
对于其他对标GPU的其他实现我们不care,特地来看一下在Raspberry Pi上的效果!!
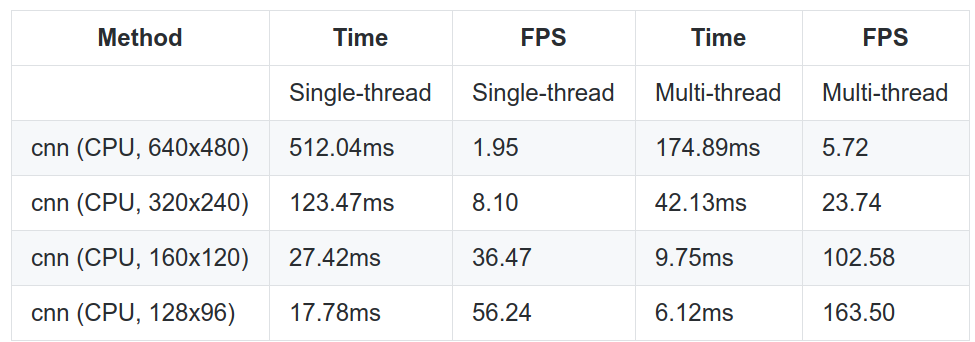
基本上可以达到 中等图片上的实时!!
欢迎大家前往编译测试!!
-
刘看山
发布在 社区求助区(SOS!!) • 阅读更多
这个其实就是python2和python3的兼容问题,用python2跑应该不会出错,如果用python3,应该在最上面添加一下:
from __future__ import divide具体不记得了,就是添加一个divide的兼容包。
另外建议错误贴文字啊!!!!!!!!!!!!!!!!!!截图很容易把服务器内存称爆!!!!!!!!!!!!!
-
刘看山
发布在 社区求助区(SOS!!) • 阅读更多
回答一下,这个问题比较大,我权且假设你是想从头入门学习目标检测这个领域。
从应用的角度讲,可以分为2D目标检测和3D目标检测,2D现在基本上很成熟了,比如我们经常听到的FasterRCNN系列,SSD系列,Yolo系列等,现在也到了大规模应用阶段,可以优化到非常快的速度。3D目标检测目前来讲还没有非常成熟的方法,这个也跟传感器的发展有关,目前还没有非常便宜的能够生成稠密点云的激光雷达。
楼主应该从2D目标检测开始。具体来讲,首先我给出下面这些锦囊:
- 框架用pytorch,否则你会在语言层面踩很多不必要的坑;
- 先把基础的部门看一下,比如nms,rpn,fpn等,最好自己实现一遍;
- 然后尝试自己实现一个fasterrcnn,这个其实不难。
你实现了自己的框架之后,基本上你就已经从入门到master了。祝你成功!
-
刘看山
发布在 猎头/企业招聘专区 • 阅读更多
欢迎各位职业招聘人士,为了对接广大的AI人才与企事业单位,我们面向所有公司、第三方猎头开辟此板块。请发帖人员遵守以下规则发布招聘贴:
- 招聘贴抬头模板:【公司名称】招聘岗位
- 帖子正文:需提供JD详情,要求,时间,地点等关键因素
奇异社区申明:所有猎头机构发帖都需要遵守诚信规则,否则将被管理员删贴子。本着为广大AI人才提供工作机会以及为企业提供一个附加渠道的原则,我们会对帖子进行严格审核。请大家自觉遵守,并请广大社区成员文明回帖,多谢合作!
-
刘看山
发布在 最新论文速递 • 阅读更多
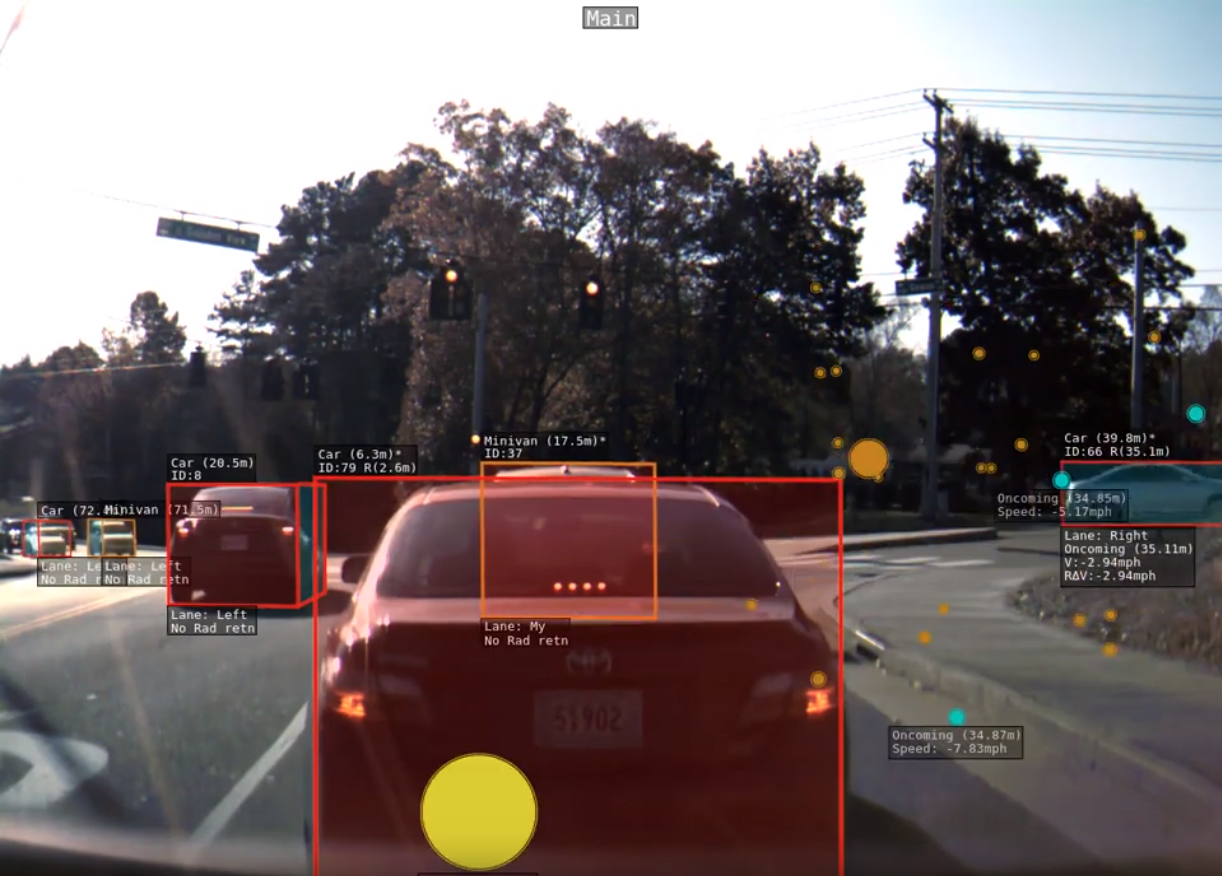
端到端实现3D目标检测 + 跟踪的文章. 这个就十分的牛逼了, 而且仅仅通过单目完成. 可以说这个十分的厉害.
并且文章开源了代码, 先放论文连接: https://arxiv.org/pdf/1811.10742.pdf
github地址: https://github.com/ucbdrive/3d-vehicle-tracking这篇文章是国立清华大学和UCBerkeley联合作的. 应该也是面向自动驾驶领域十分有用且前沿的一篇文章.
论文效果:
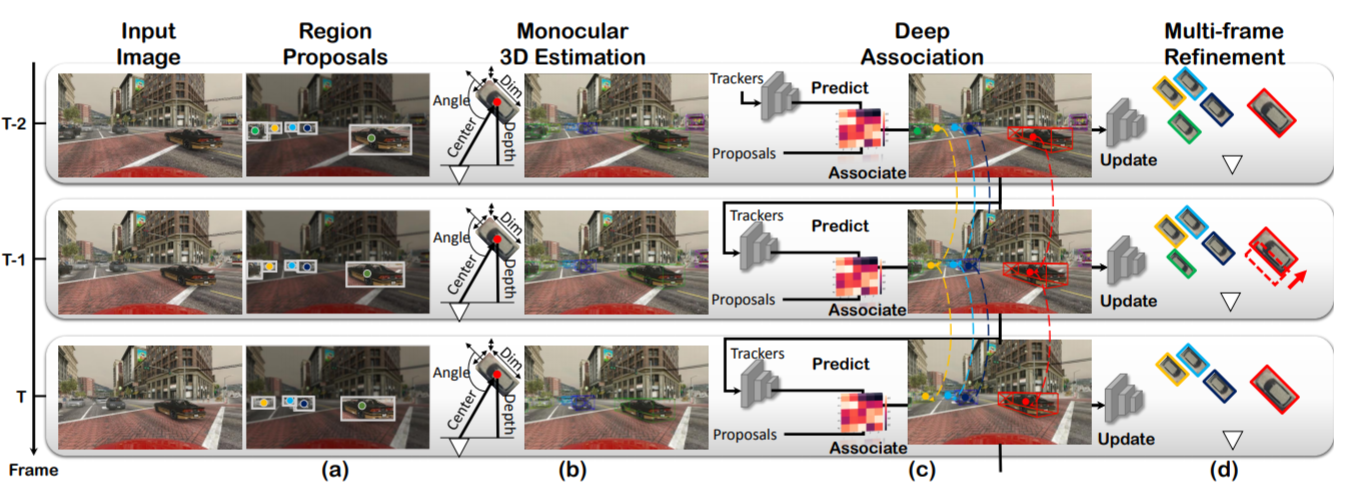

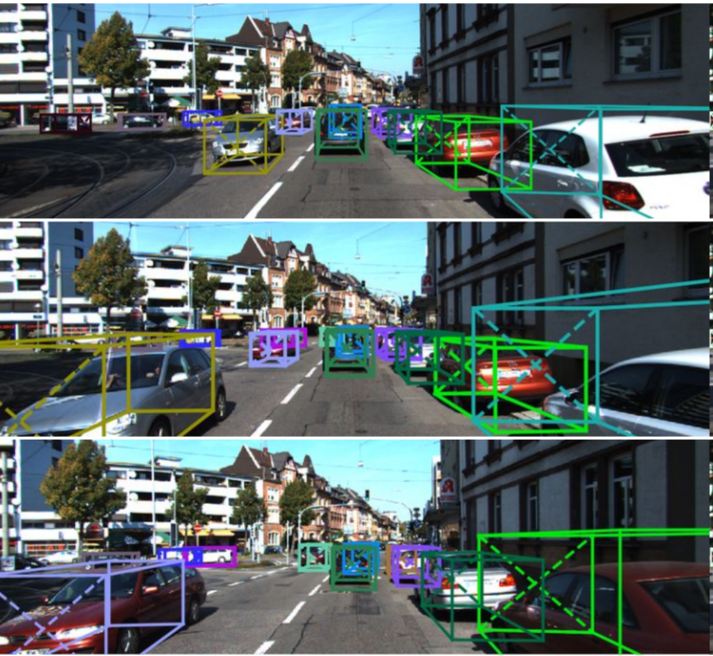
欢迎大家添加评论,来讨论交流论文中的insights
-
刘看山
发布在 社区博客 • 阅读更多
1、Hybrid Task Cascade for Instance Segmentation
速度看起来跟MaskRCNN差不多,但是值得深入跟一下。2、https://github.com/open-mmlab/mmdetection
可以模仿这个框架做一个自己的目标检测算法库。3、S3FD
这个人脸检测算法效果非常不错,适合用于小物体检测场景,但是对于类别比较多的情况效果如何就不清楚了。强化学习方向:
- oroto: http://otoro.net/ 这家公司似乎是专门做强化学习相关应用的,值得学习和模仿。
-
刘看山
发布在 社区博客 • 阅读更多
相信大家之前听说过Conernet,通过角点回归来做目标检测,然而令人震惊的是计算机视觉发展已经先进到通过中心点预测一切!!
听起来大家可能觉得没有啥,但这个方法拥有者无穷的想象和可能性,你还在为fastercnn地速度困扰?yolov3训练太繁琐?(当然这一些都很简单,来这里看看最新最快的工业级别的检测方法:http://codes.strangeai.pro )然而现在,你可以在段时间内训练一个高精度,比yolov3更快的目标检测!!最关键的是, 这个方法还能做人体姿态预测!!还能做3D 检测。手动execuse me?这么吊的方法为什么我没有听说?为什么我现在才知道?没有为什么,因为论文昨天才上线的,而你没有关注我们的专栏,更没有在这个论坛注册:http://talk.strangeai.pro 脱离AI前沿,消息闭塞,没有渠道,没有说过也很正常。当然啦,我们鲜花不多说,首先来看看效果:
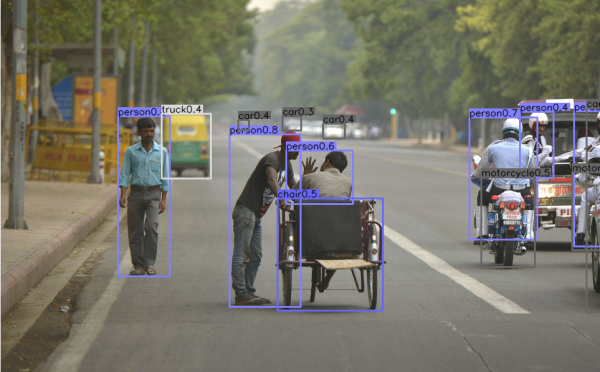
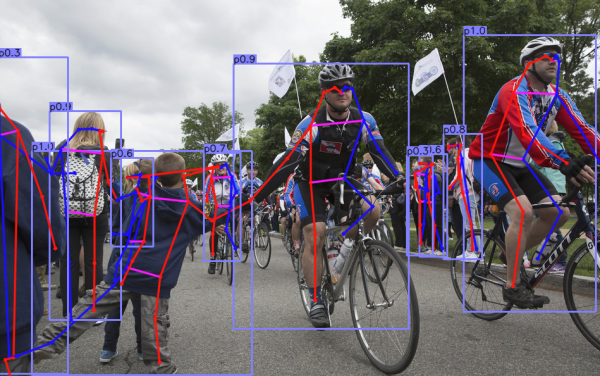
Amazing!!!,这个检测效果,我可以说非常的ok!!
最关键的我们来看一下速度,速度在当今这个追求极致的年代及其重要,这个方法的速度(GTX1080ti):
detection: 30ms;
pose: 40ms;
3D: 40-45ms.
这个速度我还能说什么?very very fast!!!!
好了,最重要的来了,这个方法实际上已经开源了!欢迎大家访问国内最大的AI算法开源平台,在这里发现众多优秀的、工业级别的部署AI算法,同时获取训练自己数据集的指导,还有机会加入我们的社群哦!
奇异AI-国内最大的AI代码平台
http://codes.strangeai.pro -
刘看山
发布在 社区求助区(SOS!!) • 阅读更多
帖子专门用来分享一些链接:
- 原始资源:https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
链接: https://pan.baidu.com/s/16c6ZcNd2bb45Wb0wZLfmiw 提取码: 2222 复制这段内容后打开百度网盘手机App,操作更方便哦
- 原始资源:https://github.com/fchollet/deep-learning-models/releases/download/v0.2/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
-
刘看山
发布在 社区求助区(SOS!!) • 阅读更多
@mindmad I think I found a good dataset to work with rotated box.
http://www.robots.ox.ac.uk/~vgg/data/hands/

those hands has a rotation angle but still a rectangle bounding box just has a rotate.
-
刘看山
发布在 原创分享专区 • 阅读更多
有时候我们想画一个函数的图像,用python其实不是最方便的。
来看看这个函数:
知道这个函数的图像是啥吗?
不是圆哦!!不要看错了上标位置。
来看看它的图像:
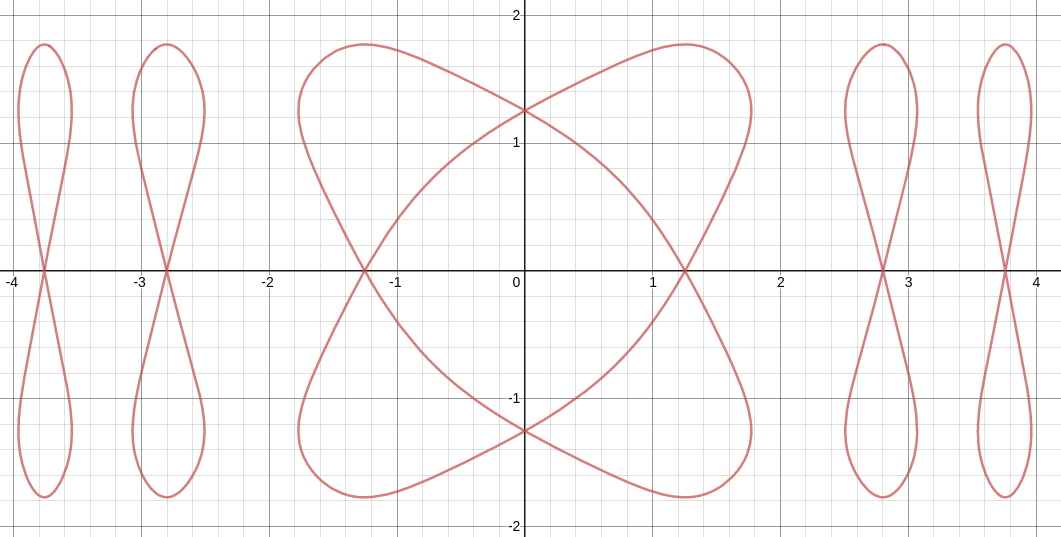
很显然这是一个对称函数,而且是闭环的。也许你用python可以画出上面那个图像,但是!!
它的真实面目你可能不知道:
把它进行缩放,你会发现这是一个很神奇的函数!!!!
它可以把自己布满在整个二维空间!!!请收藏这个有用的网址!!
https://www.desmos.com/calculator -
刘看山
发布在 原创分享专区 • 阅读更多
数据集地址:https://eurocity-dataset.tudelft.nl/
这个数据集应该是一个迄今为止最大的,最完整的,包含不同光照,场景,街道,摄像头角度的全场景行人检测数据集。并且标注还包含有行人的行进方向等信息:

对于做行人ReID,行人跟踪,行人检测,行人计数的同学们大有用途。
-
-
刘看山
发布在 原创分享专区 • 阅读更多
ONNXRuntime安装教程
onnxruntime 是个啥子?
我们都知道onnx,onnx只是一个协议格式,它没有具体的推理框架。我们知道,不同厂商,它的推理框架速度有很大的差异。我们有自己做的,比如ncnn,mnn,mace这些都是前向推理框架,他们也可以用来推理onnx模型。这是在CPU上,这些框架CPU的速度毫无疑问,比得上intel吗?比的过openvino吗?不一定。
另外一个就是GPU,你pytorch的GPU推理速度能比得过英伟达人家的TensorRT吗?比不过,至少差三倍的速度。为什么会有这么大的差别?
原因很简单,人家卖硬件的,为了让你用它的硬件,肯定会想方设法让你在硬件上速度更快,这是刚需,你对CPU的了解能比得过intel?你对GPU的了解能比得过NVIDIA??那么onnxruntime是个什么鬼呢?
onnxruntime是一个实实在在的onnx模型推理引擎,但,它统一了一个前端接口,而真正的实现支持openvino,支持mkldnn,支持TensorRT,支持CUDA,也支持CPU,换句话说,一次编写,可以直接根据硬件使用对应的库来编译。
这个很管用。那么它的速度gain到底有多大呢?
先安装一下onnxruntime吧。我们将用onnxruntime的GPU库 (不带TensorRT)来推理一下maskrcnn,看看速度和官方的pytorch、比有多大的提升。
为了加上tensorrt支持,你需要下载一下tensorrt,根据你的系统版本。解压到~/tensorrt5.1.55.1.5是最新的TensorRT。下面我们将要用到。- 安装
git clone --recursive https://github.com/microsoft/onnxruntime # 如果你遇到了libFuzzer clone不下来,从这个地方下载[Fuzzer.zip](https://github.com/alibaba/euler/files/2991980/Fuzzer.zip)解压到对应的目录,这个没有办法,Q在那儿。注意文件夹的名字不要错: https://github.com/alibaba/euler/files/2991980/Fuzzer.zip # 注意,这里把解压后的mv的时候要把.git也move过去。 ./build.sh \ --use_cuda \ --cuda_version=10.0 \ --cuda_home=/usr/local/cuda \ --cudnn_home=/usr/local/cuda \ --use_tensorrt --tensorrt_home=$HOME/TensorRT \ --build_shared_lib --enable_pybind \ --build_wheel --update --build其实也简单,通过
build.sh来编译。
可以看到,onnxruntime里面实际上有很多GPU或者CPU的实现,来支持onnx的各种operators.
如果你能开始编译,请评论一下.
onnxruntime 编译完了之后,如何进一步安装对应的python wrapper呢?
实际上已经生成了:onnxruntime 0.5.0 onnxruntime-gpu-tensorrt 0.5.0但是这个wheel文件怎么没有找到呢。。。
QA
这里记录一些onnxruntime编译的时候各种debug,请注意,我们的编译教程会随时跟踪最新的onnxruntime,记录一些常见的bug。
fatal: no submodule mapping found in .gitmodules for path 'cmake/external/gsl':
git rm --cached cmake/external/gsl 就可以xxx
xxx
onnx-tensorrt 安装教程
由于最近总是忘记onnxtensorrt如何编译。这里再记录一下,如何编译 onnx-tensorrt 以及TensorRT两个工程。
onnx-tensorrt:
git clone --recursive https://github.com/onnx/onnx-tensorrt.git cd onnx-tensorrt cmake -DTENSORRT_ROOT=~/TensorRT ..其中
~/TensorRT是你的tensorrt的安装位置。但是请注意,你要根据你的tensorrt版本去编译不同的onnx-tensorrt版本,现在master branch应该是需要tensorrt6.0 -
刘看山
发布在 原创分享专区 • 阅读更多
title: JetsonNano跑YoloV3速度评测
date: 2019-09-22 14:45:04
category: 默认分类
本文介绍 JetsonNano跑YoloV3速度评测
JetsonNano跑YoloV3速度评测
This article was original written by Jin Tian, welcome re-post, first come with https://jinfagang.github.io . but please keep this copyright info, thanks, any question could be asked via wechat:
jintianiloveu很久没有发文章了,这段时间做了很多事情,主要工作还是在于onnx模型的TensorRT加速,我们在前段时间发过很多文章讲述如何对caffe模型进行TensorRT加速,我们也有现成的算法可以用来做这件事情,通过TensorRT加速的基于Darknet53+FPN的YoloV3可以跑到~40fps,在一块decent的GPU上,这个速度已经非常快了,毕竟这个后端十分重,速度也超越了一些经典的二阶段算法,效果如下图:


可以看到几乎没有漏检,这用来进行商业化的项目部署还是很有用的,但请相信我,如果你没有TensorRT加速,Darknet53+yolov3 608的输入速度你很难做快。这个算法我们将会开源到平台,在加入更多的模型之后。因为我们需要把所有的Caffe->TensorRT的操作封装成一个库,这样部署起来就非常方便了。
当然我们的算法平台 http://manaai.cn 也更新了很多最新的项目,比如我们从零训练的手和人脸的检测器,这用来进行无人机的操控很有用途,我们几乎将所有能用得上的人手和人脸的数据集都汇聚到了一块,基于我们自己的caffe版本可以进行大规模的训练,项目地址和与训练模型 这里:

但实际上我们训练之后发现,这个模型竟然可以作为人脸的检测器:

当然效果与专业的人脸检测器还是有差距,但是毕竟速度和模型大小摆在那里。说到人脸检测器,现在很多都是评测的时候用大尺寸,比如1024x980这样的尺寸,精度上去了,但是实际上测试发现大尺寸下速度却很慢,慢到GPU上都无法实时,这就很过分了,但是除了这个算法:RetinaFace, 目前来讲是唯一一个同时兼顾速度和精度的人脸检测算法,更重要的是,这个算法可以同时拿到人脸位置和landmark,和MTCNN类似。
当然这个算法也可以在MANA平台找到,需要向大家说明的是,我们开源的是我们修改的pytorch训练版本,可以训练但是部署的时候不够快,基于onnx TensorRT加速的版本,将会在随后push到平台仓库,欢迎大家关注,预计可以做到400fps(1080尺寸输入下,GPU环境),即便是最垃圾的GPU,也能做到满实时。
最后言归正传,我们这篇文章继续上一篇的讲解。上一期我们讲到:
我们收到了一个Nvidia发过来的JetsonNano进行评测,但是不带电源,淘宝买了一个电源发现不好使,只要不运行大模型就容易崩溃。
最后发现,原来问题不是电源的问题,这里提醒一下JetsonNano的玩家:真正原因是由于我们没有短接一个跳线, 只有在短接之后板子才会从电源汲取电源而不是从usb接口.
短接之后,一切正常。这一点如果没有人告诉你,你应该不太可能知道,这就是只搞软件不搞硬件带来的偏科问题。。
YoloV3评测
本篇文章不仅仅要在Nano上评测YoloV3算法,还要教大家如何在Nano的板子上部署,并且得到我们相同的效果。所以文章可能会比较耗时,闲话短说,先来看看Nano跑起来的效果:

这里先说结论,因为相信很多读者是想用Nano来做点东西的:
- 跑Yolov3+Mobilenetv2没有一点问题,~7fps的速度我觉得是可以接受的;
- SSD+Mobilenet我没有测,但YoloV3+Mobilenet应该是精度更高一些的,输入尺寸也大一些;
- 这个是用C++跑的,我想说的是在Nano上跑caffe模型什么的一点问题都没有;
- 用在机器人视觉或者自己的项目上,你可以通过TensorRT获得更多的加速;
- 和同等级的芯片对比,比如Intel的神经网络加速棒,瑞芯的芯片等,我相信他们很难在同样的软件下达到这个速度,除非用上他们自己的神经网络加速软体套件,但这样的话,Nano就得上TensorRT大招了,毫无疑问会更快。
本期文章暂时不就Nano的TensorRT加速表现进行评测。我们可能在下一期,对几个我们训练的onnx模型进行TensorRT加速,顺便看看这些模型在Nano上能够跑到多块的速度,比如Retinaface等等。
Nano YoloV3部署教程
接下来需要传授大家如何部署了。用到的工具很简单,所有的代码来自于mana平台:
具体来说,我们需要两个项目:
- 手势操控控制无人机的caffe模型(http://manaai.cn/aicodes_detail3.html?id=43)
- YoloV3训练框架和MobilenetVOC预训练模型 (http://manaai.cn/aicodes_detail3.html?id=26)
上面的项目是我们花费了大量时间和精力训练、维护、编写、debug的开箱即用的代码,我们放在了MANA平台,如果你也是AI爱好者,想要从一些先人那里获取更多的知识和经验,不妨支持一下我们的工作,毫无疑问我们可以提供你物超所值的东西。平台代码和项目一直在更新,并永远保持最前沿。
接下来看如何部署(代码获取需要相关权限):
-
下载模型训练框架
git clone https://gitlab.com/StrangeAI/yolov3_mobilenet_caffe ~/caffe cd caffe mkdir build cd build cmake .. make -j8 make install make pycaffe这里需要注意,这个训练框架我们不需要真正训练,如果你需要训练,不要在你的Nano上进行,上面操作只是我们下面的C++程序需要调用caffe。
当然在这个过程中,你可能会遇到很多坑,但是请记住两个点:
- Nano自带了基本上所有环境,比如boost,opencv等;
- 编译错误先看错误,然后google;
- 实在不行,请来我们的AI社区交流提问,大神在线解答:http://talk.strangeai.pro
-
编写Yolov3预测C++程序
这一段我不打算贴代码,一来这个代码有点长,二来对于新手不太友好,因为还需要CMakeLists.txt的一大堆东西,大家直接clone一个现成的项目:
git clone https://gitlab.com/StrangeAI/handface_detect.git通过该项目的一些readme进行编译,只要正确链接到你clone到HOME下的caffe,这个yolov3的检测程序就是可以正确编译的。
最后提醒一下,上面的代码需要MANA会员权限,我们花费大量时间精力分享我们的源代码,并非是给伸手党一堆无用的东西,而是一些我们觉得有用的精髓,能够帮助初学者快速得到自己想要的东西,这也是我们还是新手的时候梦寐以求的,希望每一位初学者能够珍惜前人的劳动成果。当然,如果你觉得请我们喝杯咖啡显得过于炫富,也可以通过其他开源渠道获得相关代码。
如果大家对于本篇教程有任何疑问,欢迎来我们的AI交流社群交流发帖:
-
刘看山
发布在 社区求助区(SOS!!) • 阅读更多
初学者我建议两点:
-
奔着任务去学,比如你先学会分类,再学习目标检测,平台有很多项目可以参考,比如最简单的pytorch图片分类:http://manaai.cn/aicodes_detail3.html?id=30
-
不要学猴子上山,看着啥好吃就把当前的扔掉,学会一个东西先消化了再学下一个,坚持在一个问题上直到它被解决。
另外,跟着前辈的脚印走很重要。我建议加入我们的社区,看看我们每天交流,讨论的东西。耳濡目染,潜移默化。
-
-
刘看山
发布在 原创分享专区 • 阅读更多
Yolov3是一个非常好的检测器,通过这个检测器我们加入了许多最新的techniques,比如GIoU,比如ASFF,比如高斯滤波器等等,我们希望通过维护一个可以迭代的yolov3版本(我们且称之为YoloV4),可以给大家提供一个从轻量模型(mobilenet,efficientnet后端),到量化剪枝,最后到TensorRT部署,覆盖CPU和GPU的多场景检测模型。
现在我们在社区一些版本的基础上已经完成了初步的构建,比如:
下面有一个我们提供的onnx模型,希望大家一起帮忙使用tensorrt 6.0或者tensorrt7.0来转到engine,这个模型我们会经常更新,欢迎大家发帖回复更新。
目前已经测试在tensorrt6.0上缺少ConstantOfShape的op,但是在tensorrt7上似乎已经支持!
链接: https://pan.baidu.com/s/1UwJ_2iF2HH-3MCe-pe3sqg 提取码: bhxs 复制这段内容后打开百度网盘手机App,操作更方便哦
-